
Built for teams that need control at scale
- You manage high volume across inbox, tickets, chat, or multiple regions
- You need consistent standards (not person-to-person output)
- You want weekly executive visibility and clean escalation lanes

What changes at Enterprise level
Dedicated Pod + Ownership
One accountable team. Clear owner per system until closure.
Governance + Standards
Rules enforced: routing, stages, approvals, quality.
Visibility + SLA
Fixed reporting cadence + defined response windows (by scope).
Enterprise modules
Enterprise Ops Pod
Dedicated Team + Service Targets
A dedicated operations pod runs your workflows under defined coverage, SLAs, and ownership. Execution follows locked SOPs, priority lanes, and approval paths, with weekly leadership visibility. Built for teams that need reliability at scale.
Revenue Ops Governance
Rules + Ownership + Pipeline Hygiene
We enforce standards across lead flow, CRM stages, handoffs, and follow-ups so revenue operations stay controlled. Rules are documented, reviewed weekly, and exceptions are flagged before leakage happens.
Support Command Center
Quality Control + Priority Handling + Coaching
High-volume support is managed through governed queues, escalation rules, QA reviews, and operator coaching. Urgent cases follow defined paths, not guesswork—keeping customer experience consistent as volume grows.
Systems Reliability
Automations + Integrations + Data Hygiene
Critical automations, integrations, and data flows are monitored to prevent silent failures, sync issues, and reporting drift. Fields, tags, routing rules, and system logic stay clean and dependable.
Weekly Visibility & Reporting
Decision-Ready Ops Snapshot
Every week, leadership gets a structured snapshot of execution status, risks, blockers, escalations, and upcoming priorities. Visibility is standardized so decisions are based on signal, not noise.
Knowledge Base & Self-Serve
Documented Execution + Operator Enablement
SOPs, playbooks, routing rules, and FAQs are documented and maintained so execution doesn’t depend on individuals. This reduces errors, speeds onboarding, and keeps delivery consistent.
Enterprise modules operate under fixed scope, governed execution, and weekly cadence. Structure stays the same as volume grows — only scope expands.
Proof of how this runs
Real workflows and real deliverables — so you can see the system before you buy.
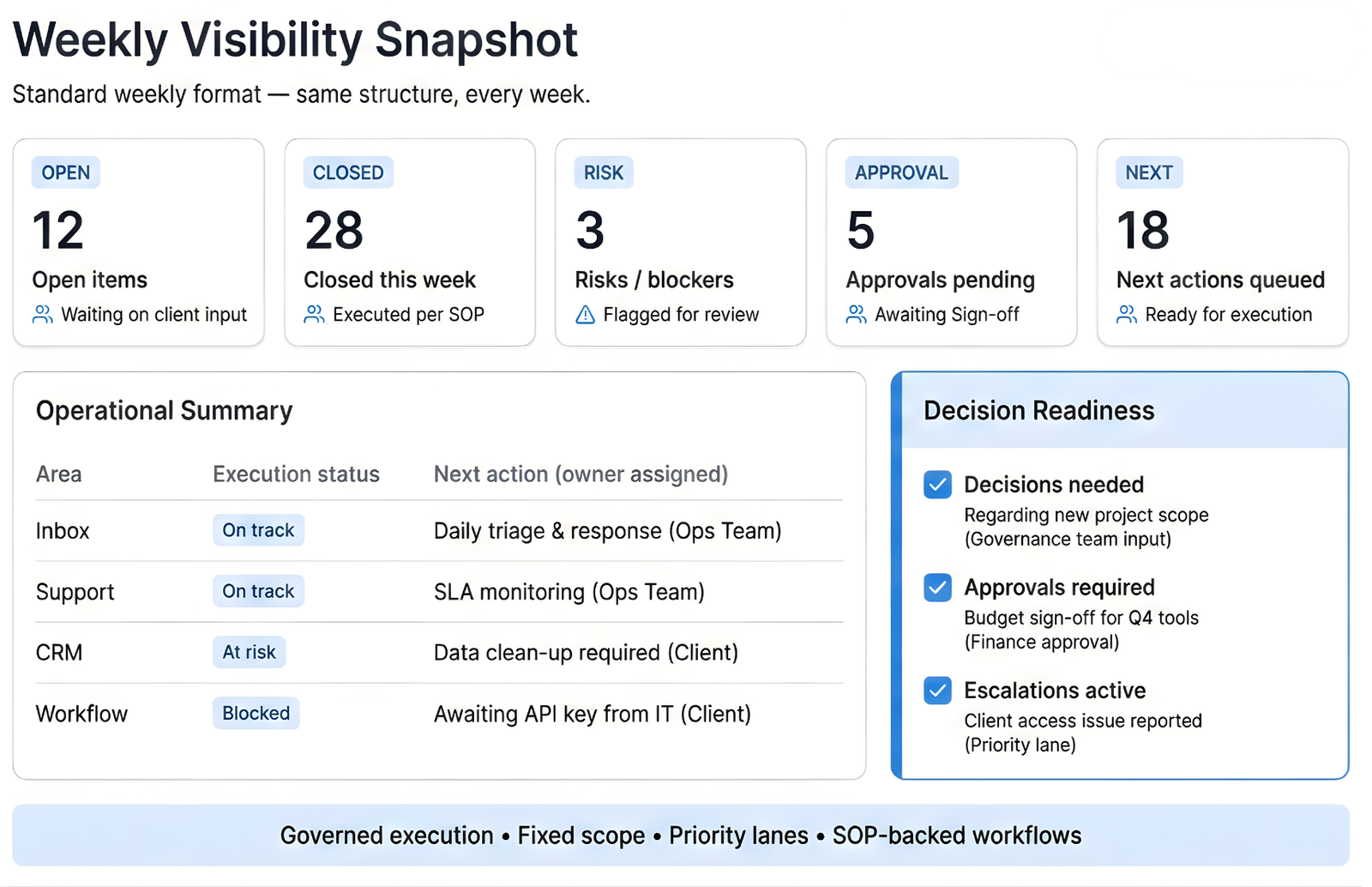
Weekly Visibility Report (Sample)
What it is
A fixed weekly snapshot that shows exactly what moved, what’s stuck, and what needs decisions.
What you’ll see
- Completed vs open work (clear status)
- Risks & escalations flagged early
- Approvals needed + next-week priorities
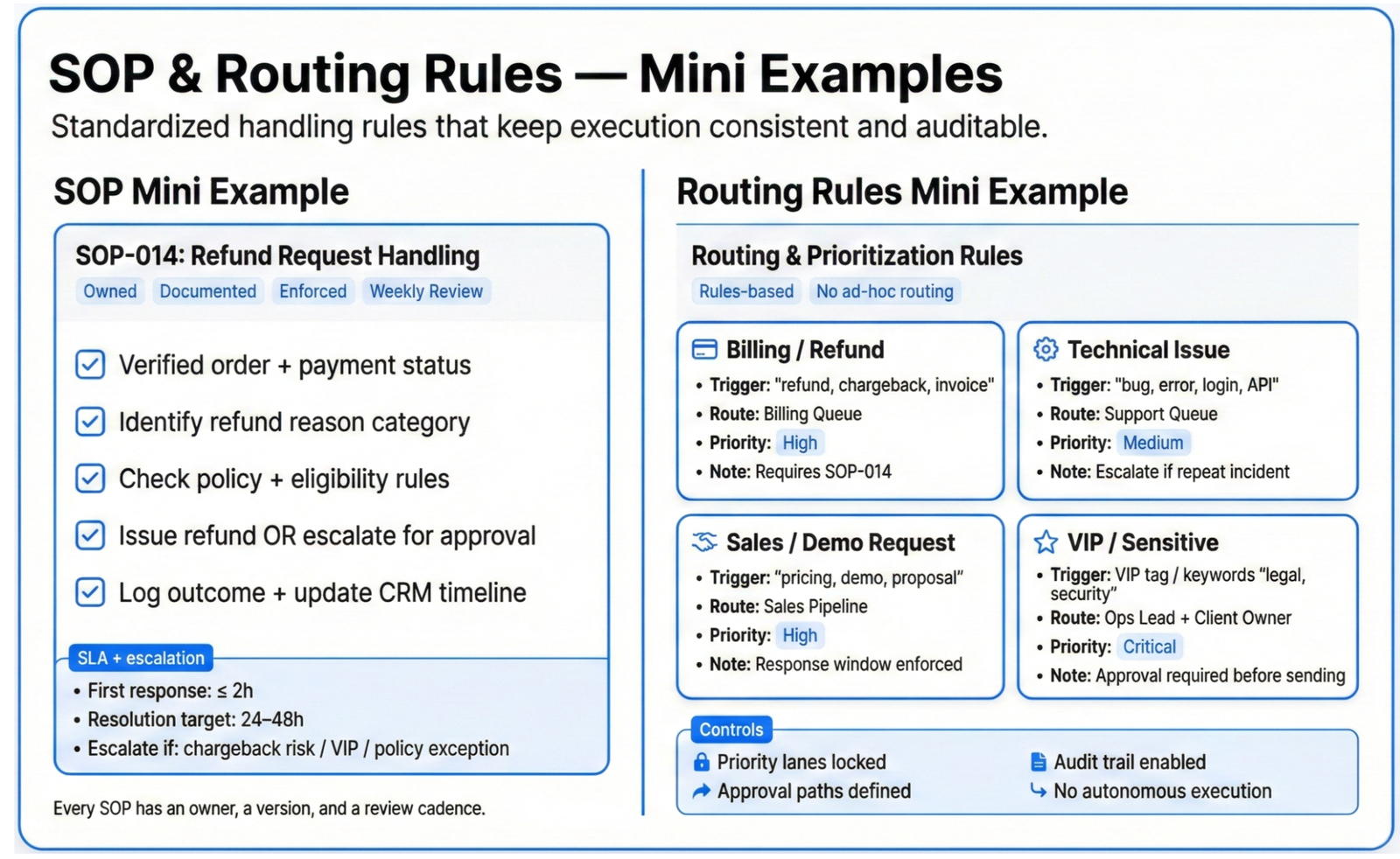
SOP & Routing Rules (Mini Example)
What it is
A real example of how work is tagged, routed, and escalated — not theory.
What you’ll see
- Priority lanes (P1 / P2 / P3)
- Ownership rules + escalation paths
- Approved templates / macros in use
Coverage & Response Windows
What it is
Clear working hours, priority lanes, and escalation rules — no ambiguity.
What you’ll see
- Defined working hours + timezone
- Priority response lanes
- SLA / targets defined by scope (Enterprise)

Tools & Stack Compatibility
What it is
We operate inside your existing stack. No forced migrations.
What you’ll see
- Gmail, Outlook, Zendesk, Intercom
- HubSpot, Pipedrive, Notion, Slack
- If you use another tool, we can run it if it fits scope
Samples shown for clarity. Final fields, cadence, and depth vary by scope, tools, and volume.

What you get (every week)
- Weekly ops summary (completed / open / risks / approvals)
- Open loops tracker (waiting, follow-ups, blocked with reason)
- CRM/pipeline hygiene notes (stale items, next steps, stage accuracy)
- Decision queue (what needs your approval)
- Next-week priorities (top focus + owners)
- Format stays consistent every week—no surprises.
Security & access handling
- Least-privilege access (role-based)
- Password manager supported (1Password / Bitwarden)
- NDA available
- Access removal + handoff rules on exit
- Work updates recorded in agreed system (CRM / Notion / ticketing)
Service targets (defined by scope)
- Daily progress on in-scope work
- Risks flagged early with recommended next steps
- Weekly visibility delivered on a fixed cadence
- Response windows and coverage defined in the scope document
Controls that protect delivery
- Scope control: clear in-scope vs out-of-scope
- Change control: review → apply → log (simple change log)
- Escalation lanes: urgent, revenue, sensitive cases
- Quality checks: QA sampling where included
- Governance cadence: weekly exceptions + monthly operating review

What are Enterprise Ops Pods?
Dedicated teams built for high-volume, multi-tool operations with tighter controls.
When should I choose enterprise?
When volume, complexity, or risk requires stronger governance and escalation paths.
Are resources dedicated in enterprise plans?
Yes. Enterprise pods include dedicated ops coverage and QA.
How is quality controlled at scale?
Via SOP enforcement, QA reviews, escalation rules, and leadership reporting.
Is enterprise pricing fixed?
No. Pricing is scope-based and finalized after review.
Ready for an enterprise setup that stays controlled?
Request an Enterprise Scope Review—we’ll confirm volume, tools, modules, and governance cadence.